






StalkerOK
CEO
FB-killa team
- Регистрация
- 6 Мар 2017
- Сообщения
- 4.551
- Ответов на вопросы
- 42
- Реакции
- 2.672
Вы знаете аудитории в Facebook на основе списка подписчиков или данных отслеживания пикселя. Их используют практически все. Однако есть виды, которые не так популярны, но при этом приносят высокую конверсию. В этой статье – их обзор, со способами применения.
Почему вы могли не знать об этих аудиториях
Все просто – они «прячутся» в разделе «Вовлеченность на Facebook»:
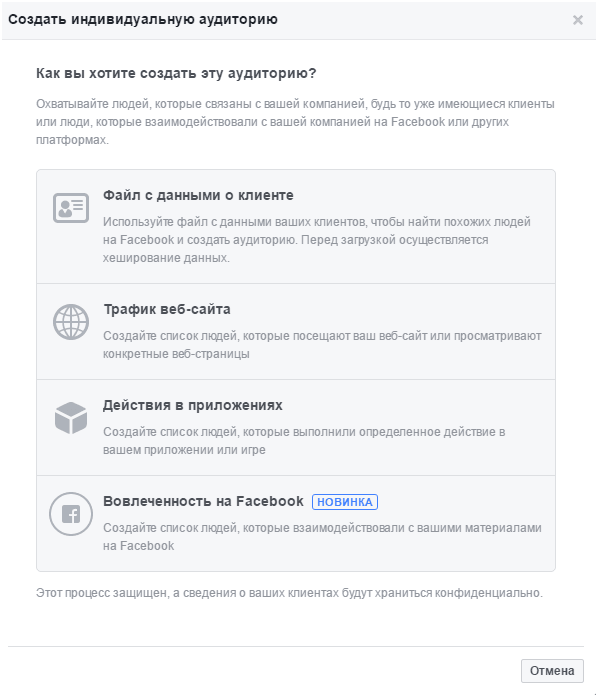
Для многих важнее трафик сайта, а не вовлеченность аудитории, поэтому они не доходят до конца списка. Это большое упущение. Ведь потенциальные клиенты все чаще взаимодействуют с компаниями в соцсети.
Следующие действия пользователя дают информацию о том, на каком этапе воронки он находится. Создавайте аудитории на их основе и применяйте в ретаргетинговых кампаниях.
Просмотры видео
Видеореклама – отличный способ познакомить холодную аудиторию с брендом или продуктом.
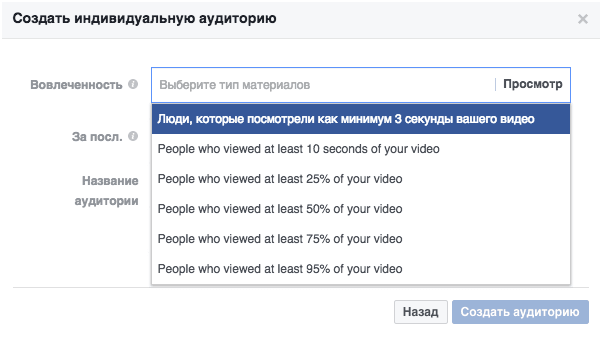
Facebook позволяет сделать таргетинг более специфичным – по проценту или продолжительности просмотра:
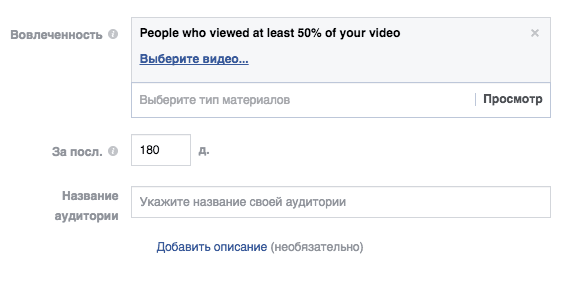
Можно настроить одновременно несколько роликов по этим критериям и указать период вовлечения:
В ретаргетинговое объявление включайте цепляющий оффер и / или лид-форму, которые побуждают совершить целевое действие (покупку, заказ, заявку, подписку).
Взаимодействие с рекламой для сбора лидов
Благодаря последнему обновлению, аудиторию можно формировать не только из пользователей с Facebook, но и с Instagram.
После клика по объявлению – в мобайле или десктопе – человек видит форму с контактными данными, которые он ранее сообщил Facebook. Для него просто совершить желаемое действие, для вас – собирать качественные лиды.
Выберите признак из списка:
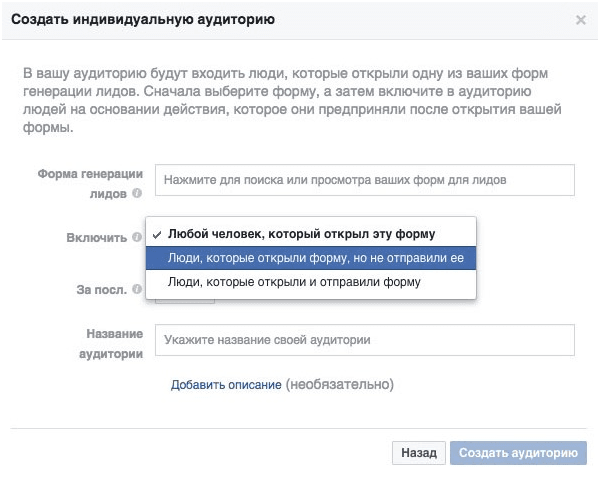
Если пользователи открывают форму, но не отправляют, привлеките их с помощью ретаргетинга на сайт, где они могут изучить больше информации о вас самостоятельно. Если форму отправили, «бейте» четкими офферами, чтобы добиться конверсии.
Взаимодействие с событиями
Эта возможность появилась всего пару недель назад.
Многие компании размещают в соцсети события – от вебинаров до открытий магазинов. Ретаргетинг на основе мероприятия позволяет создать персонализированный месседж для пользователей, которых оно интересует и / или которые его посетят.
Цель относительно первых – повысить посещаемость среди них с помощью продающего объявления. Посетителям события покажите другие продукты и сервисы для апселлинга. Эта теплая аудитория, так как они уже оплатили посещение.
Взаимодействие с аккаунтом Instagram
Чтобы использовать эту возможность, нужен бизнес-профиль в Instagram.
Вот критерии для ретаргетинга:
У Instagram в среднем показатели вовлеченности выше, чем у Facebook. Возможны и различия в аудитории подписчиков.
Ретаргетинговая кампания с персонализированными офферами поможет продвигать их от стадии обдумывания к стадии покупки.
Единственный недостаток – нельзя настроить таргетинг на пользователей, которые взаимодействовали с конкретным постом, объявлением или видеороликом.
Источник
Почему вы могли не знать об этих аудиториях
Все просто – они «прячутся» в разделе «Вовлеченность на Facebook»:
Для многих важнее трафик сайта, а не вовлеченность аудитории, поэтому они не доходят до конца списка. Это большое упущение. Ведь потенциальные клиенты все чаще взаимодействуют с компаниями в соцсети.
Следующие действия пользователя дают информацию о том, на каком этапе воронки он находится. Создавайте аудитории на их основе и применяйте в ретаргетинговых кампаниях.
Просмотры видео
Видеореклама – отличный способ познакомить холодную аудиторию с брендом или продуктом.
Facebook позволяет сделать таргетинг более специфичным – по проценту или продолжительности просмотра:
Можно настроить одновременно несколько роликов по этим критериям и указать период вовлечения:
В ретаргетинговое объявление включайте цепляющий оффер и / или лид-форму, которые побуждают совершить целевое действие (покупку, заказ, заявку, подписку).
Взаимодействие с рекламой для сбора лидов
Благодаря последнему обновлению, аудиторию можно формировать не только из пользователей с Facebook, но и с Instagram.
После клика по объявлению – в мобайле или десктопе – человек видит форму с контактными данными, которые он ранее сообщил Facebook. Для него просто совершить желаемое действие, для вас – собирать качественные лиды.
Выберите признак из списка:
Если пользователи открывают форму, но не отправляют, привлеките их с помощью ретаргетинга на сайт, где они могут изучить больше информации о вас самостоятельно. Если форму отправили, «бейте» четкими офферами, чтобы добиться конверсии.
Взаимодействие с событиями
Эта возможность появилась всего пару недель назад.
Многие компании размещают в соцсети события – от вебинаров до открытий магазинов. Ретаргетинг на основе мероприятия позволяет создать персонализированный месседж для пользователей, которых оно интересует и / или которые его посетят.
Цель относительно первых – повысить посещаемость среди них с помощью продающего объявления. Посетителям события покажите другие продукты и сервисы для апселлинга. Эта теплая аудитория, так как они уже оплатили посещение.
Взаимодействие с аккаунтом Instagram
Чтобы использовать эту возможность, нужен бизнес-профиль в Instagram.
Вот критерии для ретаргетинга:
- Вовлечение в профиль;
- Посещение профиля;
- Вовлечение с помощью поста или объявления;
- Клики по CTA;
- Отправка сообщений профилю;
- Сохранение страницы профиля или поста.
У Instagram в среднем показатели вовлеченности выше, чем у Facebook. Возможны и различия в аудитории подписчиков.
Ретаргетинговая кампания с персонализированными офферами поможет продвигать их от стадии обдумывания к стадии покупки.
Единственный недостаток – нельзя настроить таргетинг на пользователей, которые взаимодействовали с конкретным постом, объявлением или видеороликом.
Источник

